Create a new run on VESSL
Enjoy your interactive works
Using YAML
Configuring your run through a YAML file offers several advantages:- Ease of configuration: Simplifies editing everything from resources to volume mounts across various cloud providers.
- Reproducibility: Enables the exact replication of an AI model with a single configuration file.
- Version control: Facilitates easy versioning of the run configuration.
YAML reference
View a comprehensive list of the YAML schema available for configurations.
Using the VESSL Hub
The VESSL Hub hosts curated, state-of-the-art open source AI models, each paired with a YAML file for easy import. Simply navigate to the model of choice and execute the run with one click. Visit VESSL Hub to get started.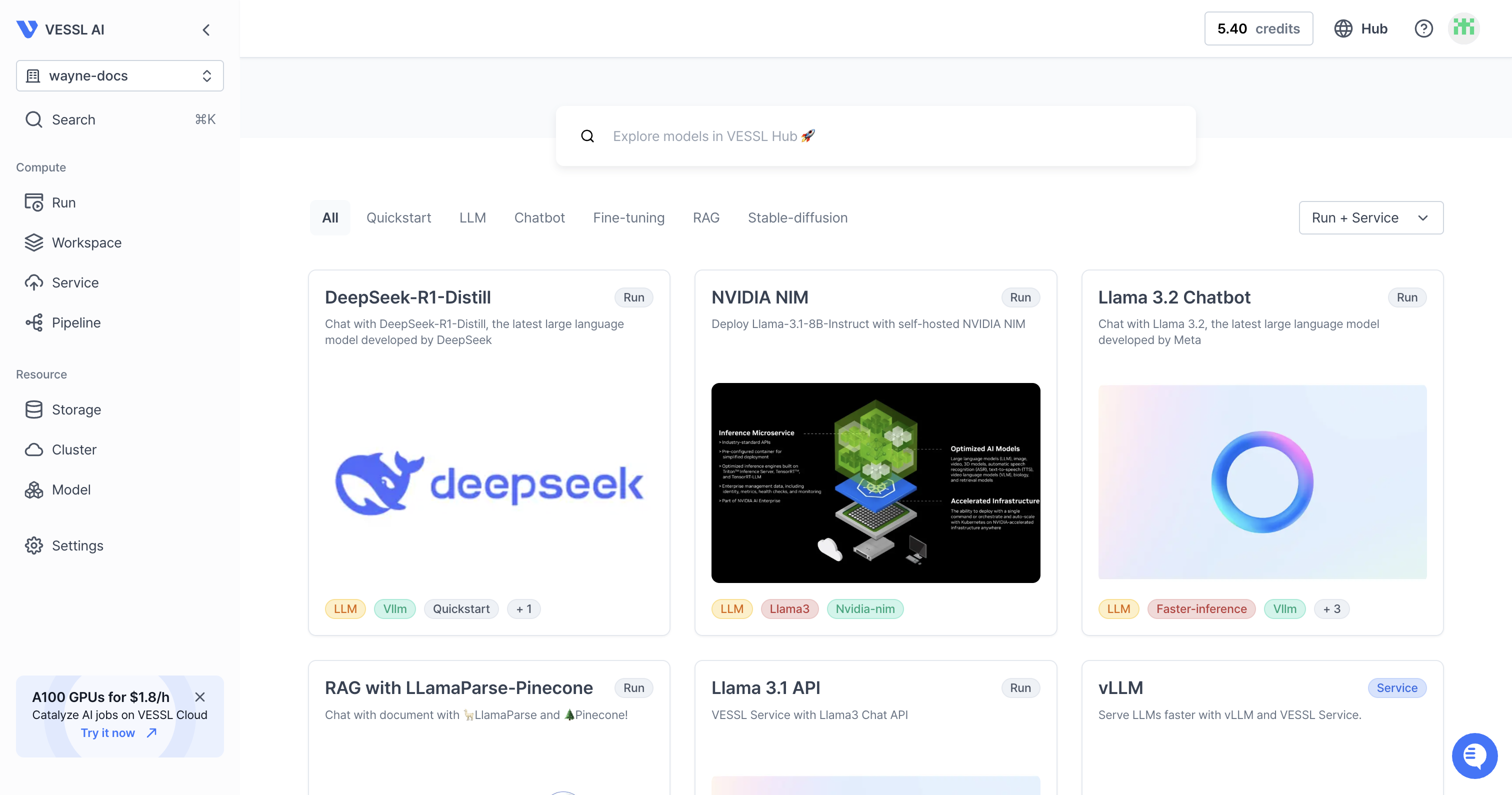
Using Command Line Interface (CLI)
Install and set up the VESSL CLI with these commands:Create a project
1
Create a project
First, you need to create a project.
2
Create a run in the project
Then, you can create a run in the project.
3
Create a run by specifying the YAML configuration file
Create a run by specifying the YAML configuration file:
Using the web console
Initialize a run with the options
You can create a run in the web console by following these steps:1
Create a project
You can create a project by using the web console.
If you want to make this project private, you can check the Check to make this project private checkbox.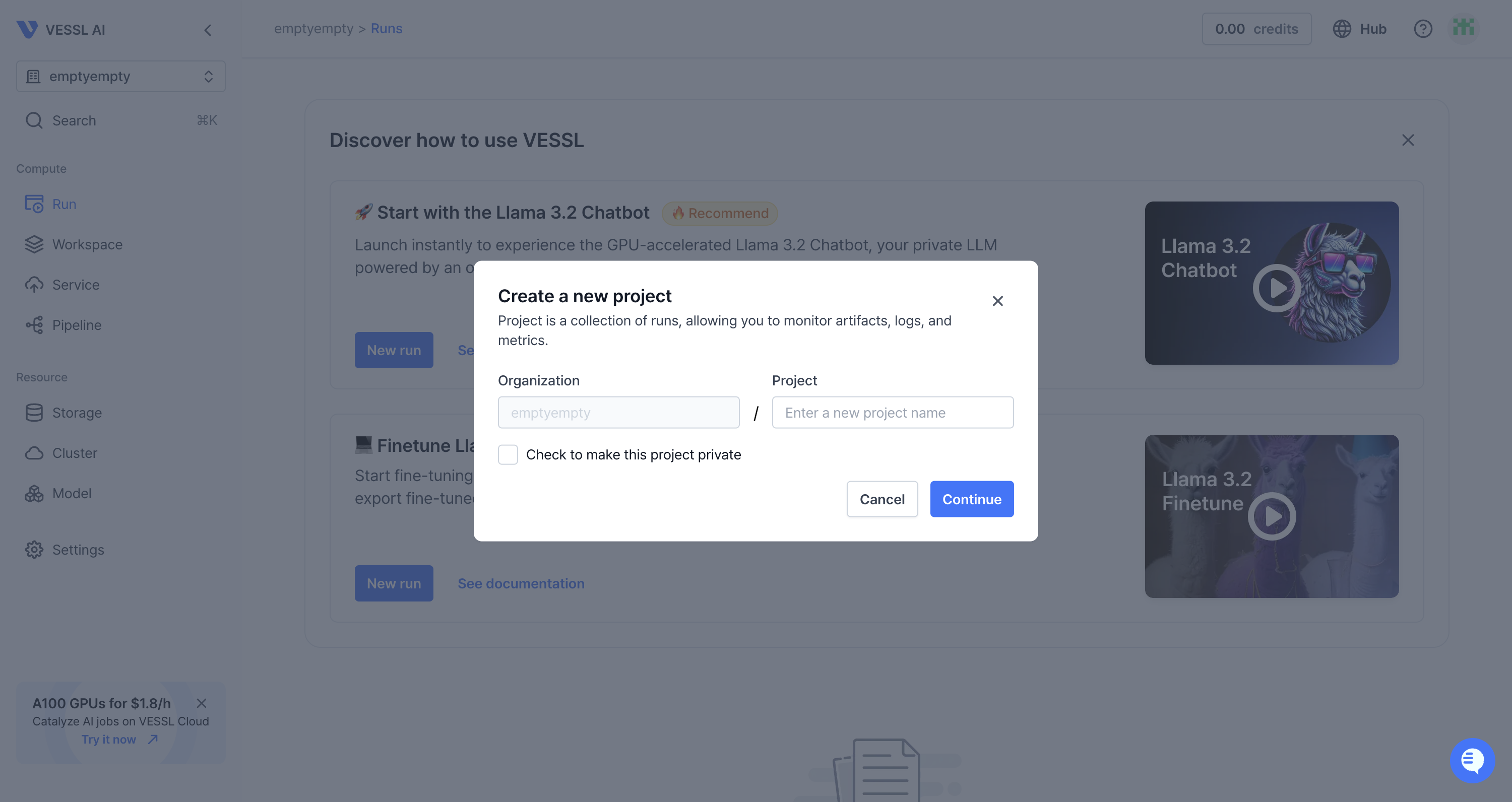
If you want to make this project private, you can check the Check to make this project private checkbox.
2
Create a run in the project
You can create a run in the project by using the web console.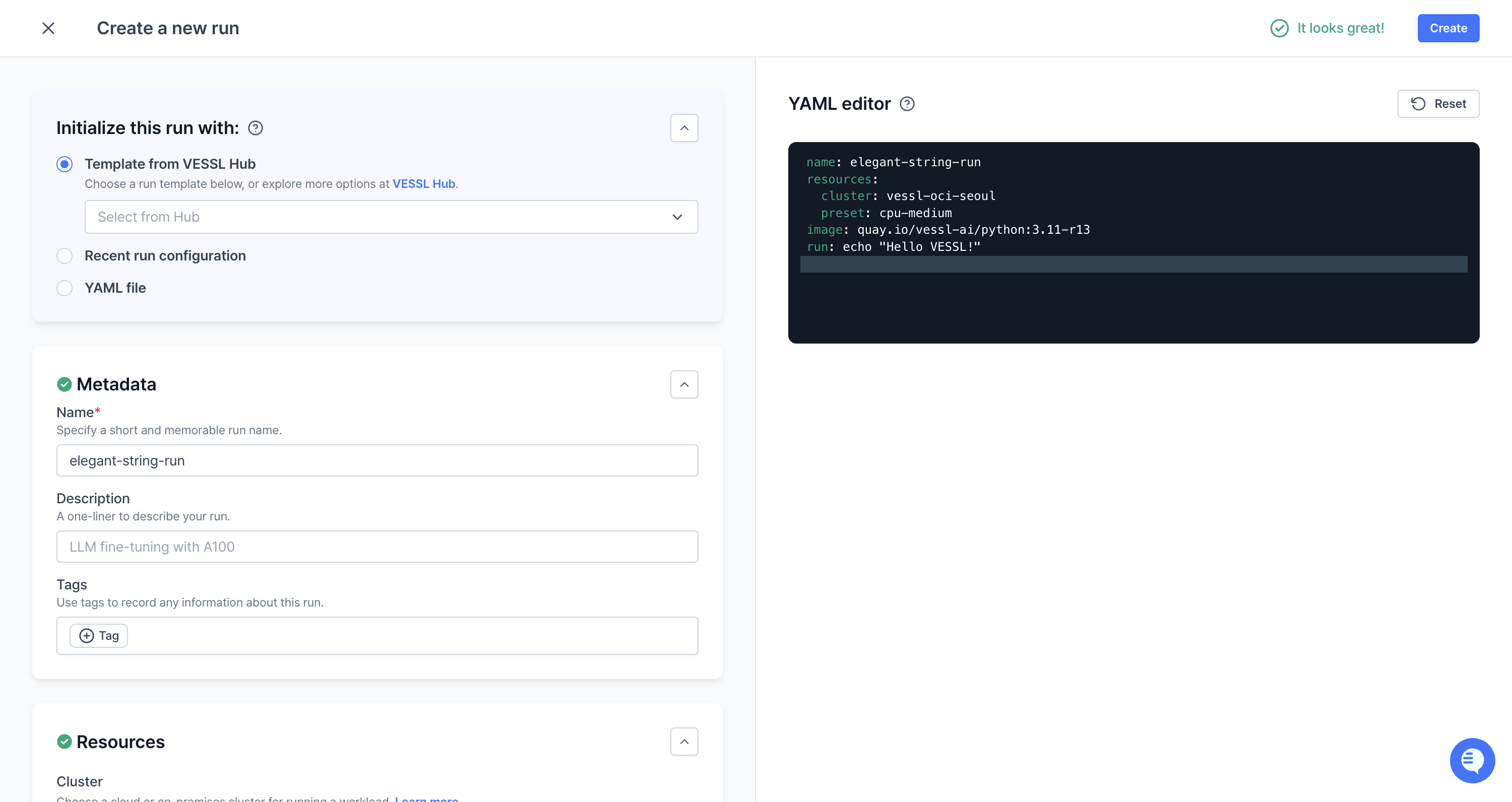
3
Initialize a run with the options
You can initialize a run with the options by using the web console.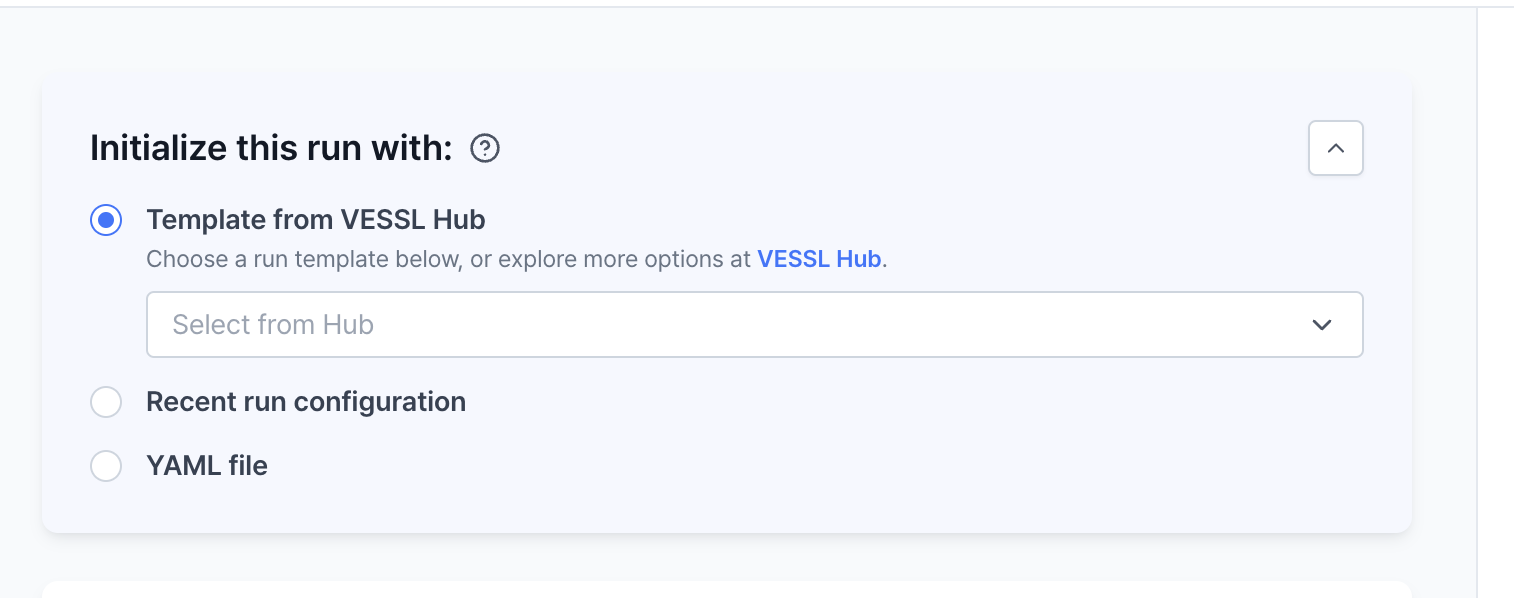
- Template from VESSL Hub: You can import and run the pre-built model from VESSL Hub.
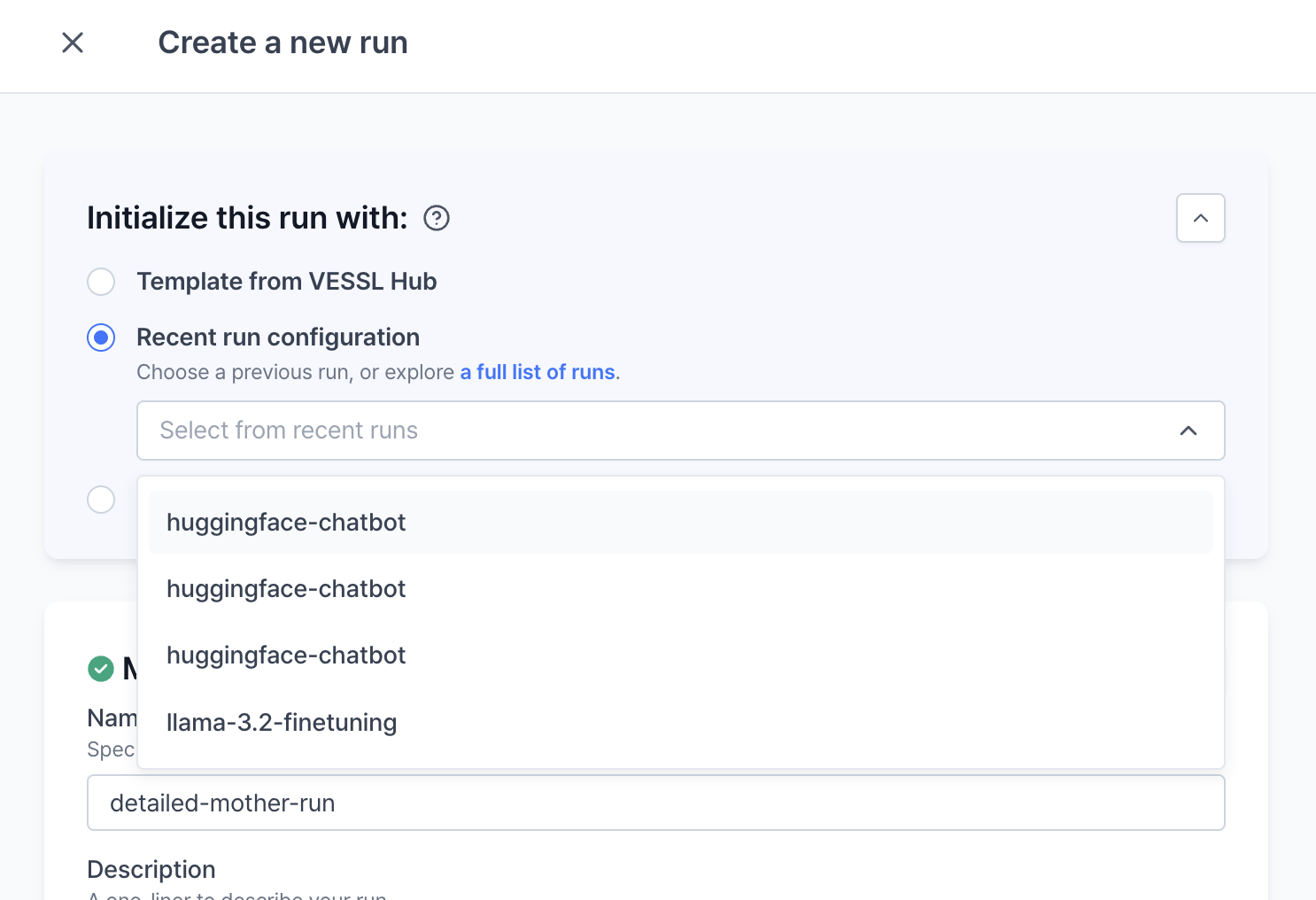
- Recent run configuration: You can import and run the recent run configuration from VESSL Run.
- YAML file: You can import and run the YAML file that stored in your local storage.
Template from VESSL Hub
VESSL Run supports the import of use cases and examples in the form of templates from VESSL Hub. These use cases and examples are built using state-of-the-art machine learning models, including audio, image, large language models, and libraries.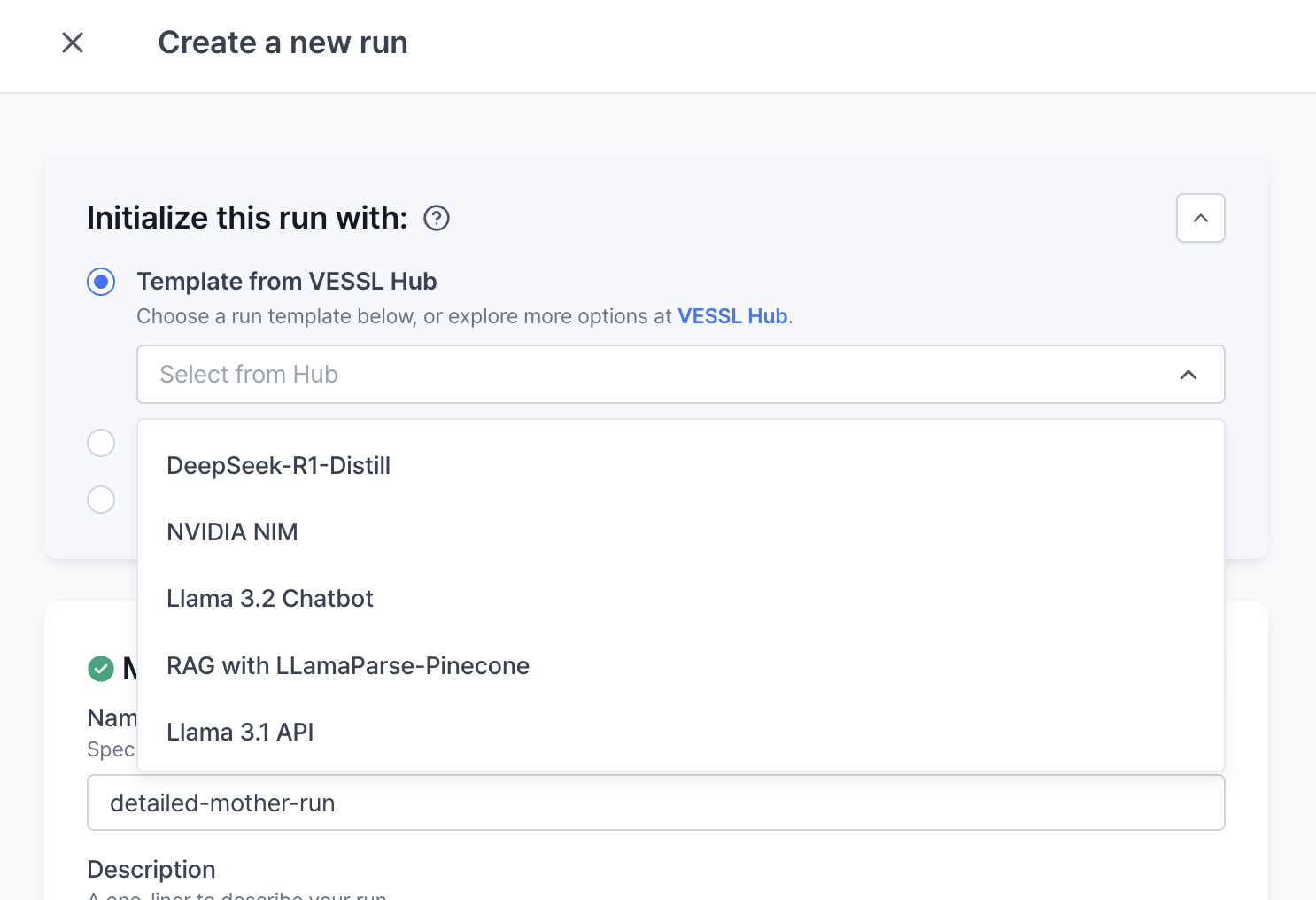
Template from VESSL Hub, you can browse numerous models. This feature allows you to quickly create a run.
Click to view the lists of the templates on VESSL Hub
Click to view the lists of the templates on VESSL Hub
- DeepSeek-R1-Distill
- NVIDIA NIM
- Llama 3.2 Chatbot
- RAG with LLamaParse-Pinecone
- Llama 3 Chatbot
- vLLM (with Prometheus Monitoring)
- RAG with LangChain
- Llama 3.2 Fine-tuning
- Face to Sticker
- Stable Diffusion WebUI
- Llama 3 Chat API
- Gemma 2 Chat API
- Whisper v3
- SSD-1B
- Create your own
- Mistral 7B
- Segmind VegaRT
- TimesFM
- TGI Service
- vLLM Service
- DeepCache
- LCM-LoRA
- Instance Diffusion
- Stable Cascade
- Gemma 2B-IT
- MusicGen
- MotionGPT
- Vec2Text
- ViPE-Videos
- Cross-Lingual Consistency (CLC)
- Papermage
- Machine Translation Metrics Evaluation (MTME)
- LLaVa-inference
- Jupyter Notebook
Recent run configuration
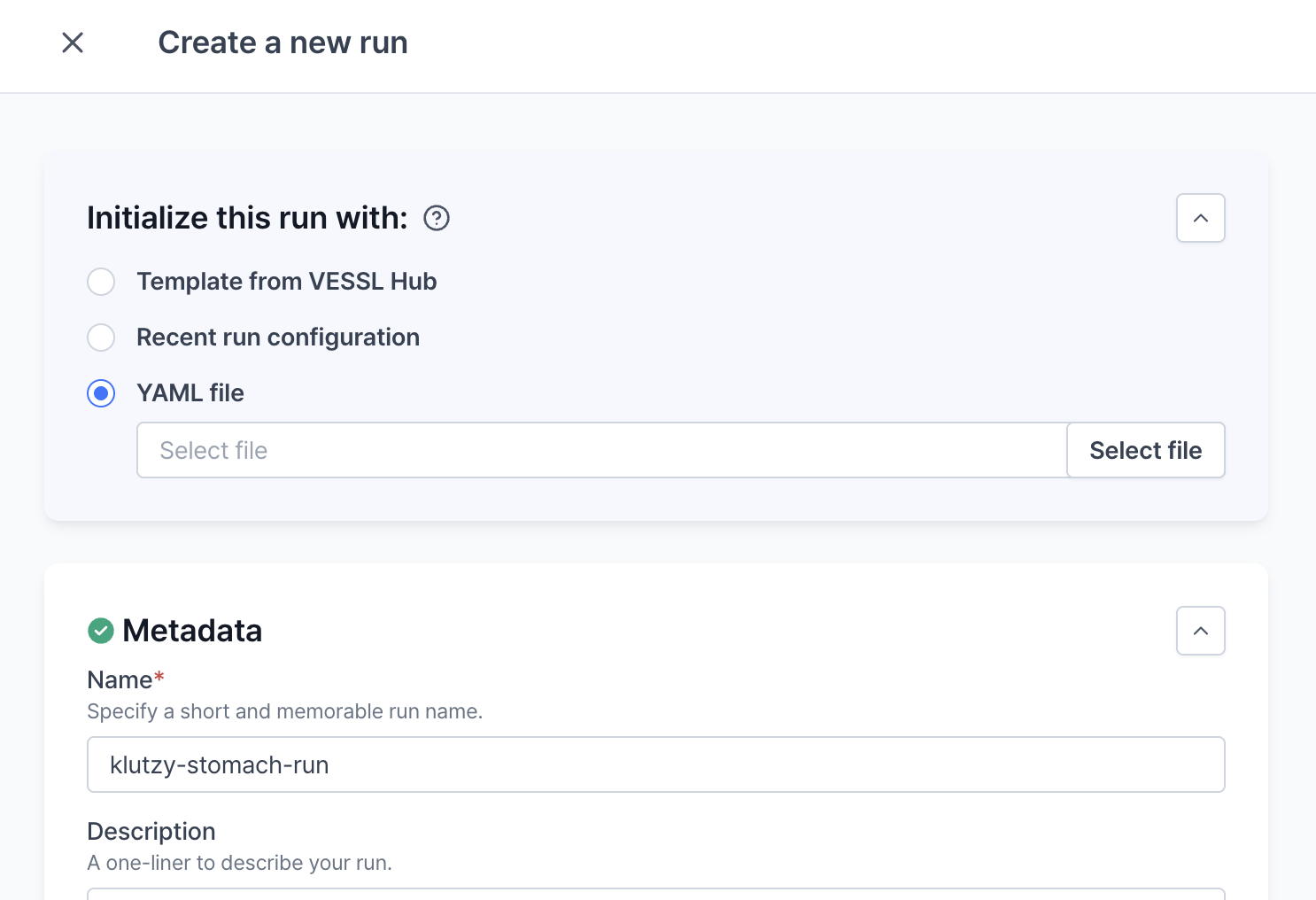
YAML file
You can import a custom YAML file using this initialization option. Click theSelect file button to import your YAML file from local storage. After the upload is complete, you will see your customized YAML file content in the YAML editor on the right side of the page.
Metadata
Metadata provides essential information about each run, enhancing organization, searchability, and identification within your project. Setting this accurately is critical to ensure efficient management and easy retrieval of runs.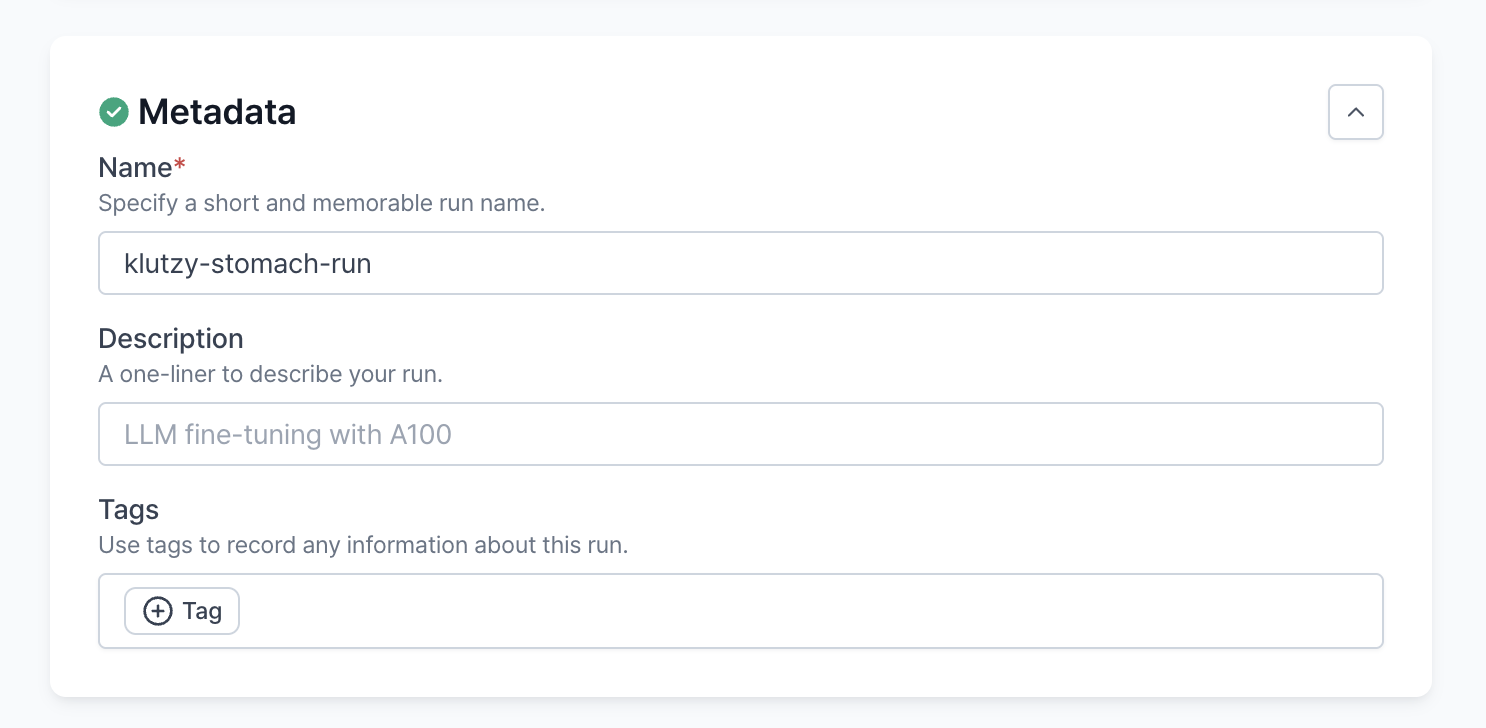
- Name: Assign a unique and descriptive name to each run. This helps in quickly identifying the purpose of the run across various project stages.
- Description: Provide a concise summary of the run’s objectives, configurations, or any specific notes that would help in understanding its purpose and scope at a glance.
- Tags: Use tags to categorize and filter runs based on key characteristics such as the model type, experiment phase, team, or any other relevant criteria. Tags support efficient sorting and grouping of runs, making them easier to navigate and analyze.
Resources
When setting up a run, specifying the appropriate resources is crucial. VESSL supports a hybrid approach, leveraging both cloud-based resources and on-premises servers. Each run is effectively containerized to ensure scalability and flexibility across different environments.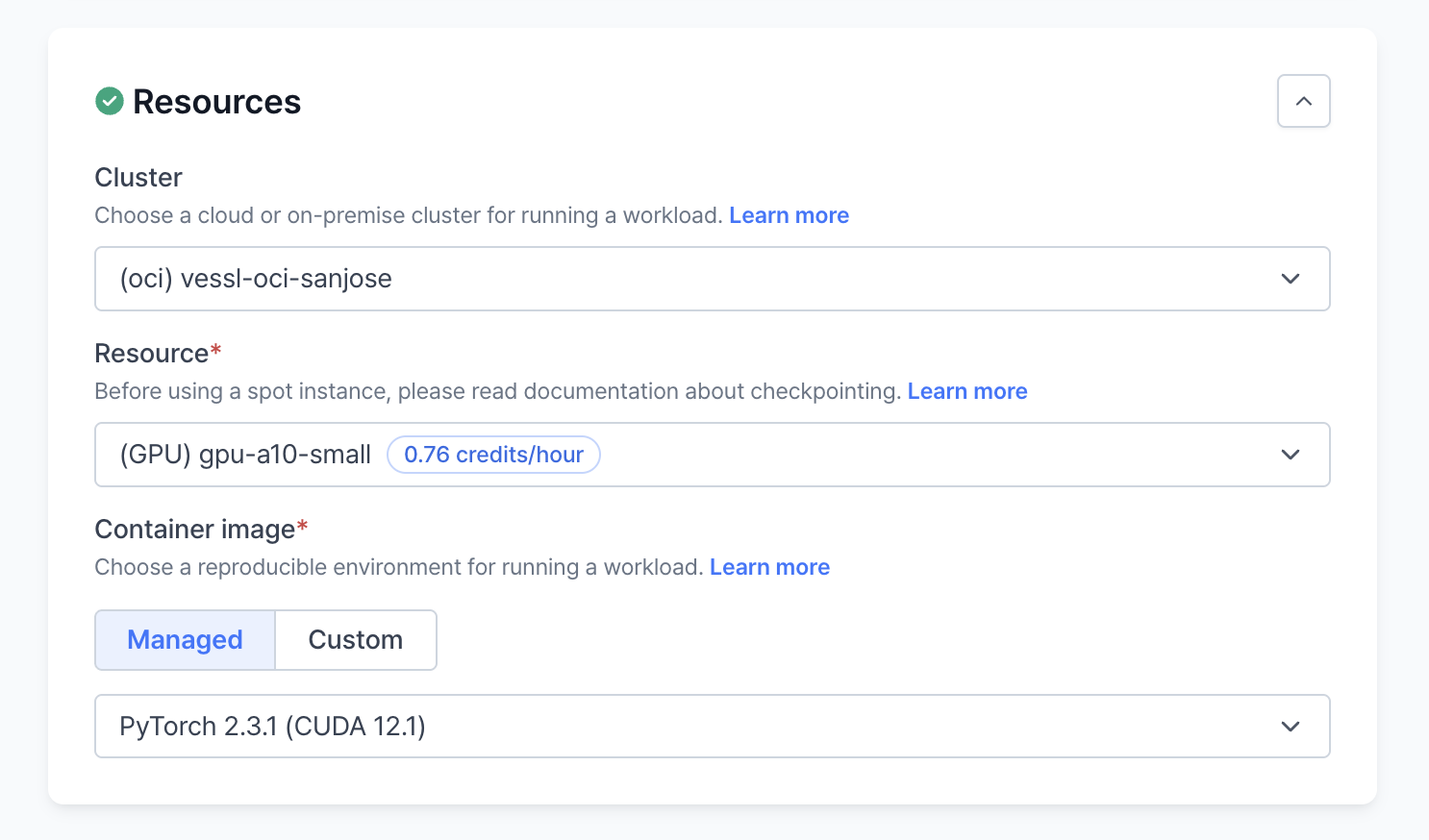
Cluster
Select the optimal execution environment for your run by choosing between a VESSL-managed cluster and a custom cluster:- Managed Cluster: Choose from a list of pre-configured resources available through a dropdown menu, designed to simplify setup and deployment.
- Custom Cluster: For more specific needs, such as utilizing on-premises hardware or particular cloud configurations, specify your custom requirements to tailor the cluster to your needs.
Resource
VESSL offers predefined resource specifications for both CPUs and GPUs, which helps in efficiently scaling your application:- GPU Specs: Choose based on the number of GPUs required:
small= 1 GPUmedium= 2 GPUslarge= 4 GPUsxlarge= 8 GPUs
- Spot Instances: For cost efficiency, especially with larger computational tasks, opt for spot instances. These can be identified by the postfix
-spotin the preset name (for example, cpu-small-spot, gpu-l4-small-spot), offering the same resources at a potentially lower cost due to the use of reclaimed capacity.
Container Image
Choose between using a VESSL-managed or a custom container image.- Managed Image: Select from pre-pulled images based on common requirements like NVIDIA GPU Cloud (NGC) images.
- Custom Image: Upload from Docker Hub or Amazon ECR, handling both public and private registries.
Task
In a typical setup, a run container functions akin to a batch job, executing a series of predefined commands with associated volumes mounted. Additionally, network settings such as interactivity options and port configurations can be managed within this framework.Volumes
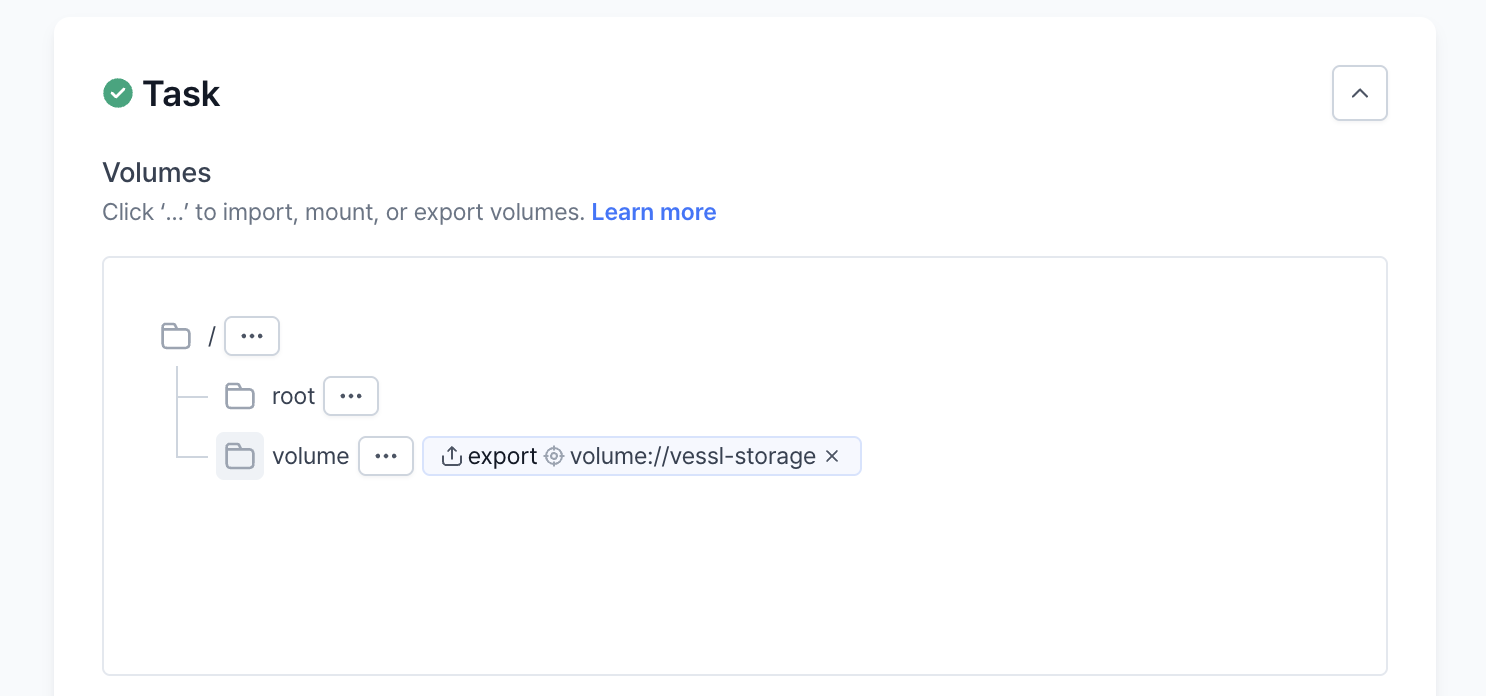
- Import: Import volumes are essential for bringing necessary files into the container at startup. Typical uses include:
- Code: Pull code from version control systems such as GitHub, GitLab, or BitBucket.
- Dataset and Model: Retrieve datasets or models defined in VESSL Dataset or VESSL Model.
- Hugging Face: Fetch datasets or models from Hugging Face repositories.
- Files: Incorporate files uploaded locally.
- Object Storage: Download data directly from cloud services like AWS S3 or Google Cloud Storage.
- Mount: Mount volumes provide persistent storage solutions, directly attaching to the run container for ongoing data access. They are particularly valuable for:
- Dataset: Attach datasets predefined in VESSL Dataset for direct use in the container.
- On-premises Storage: Connect to on-site data storage solutions using Network File System (NFS) or host path configurations.
- GCS Fuse: Integrate Google Cloud Storage using GCS Fuse for seamless data accessibility. Learn more about GCS Fuse mount.
- Export: Export volumes are used post-run to save outputs like logs, results, and models, essential for continuity and analysis. Common applications include:
- Dataset and Model: Store output data back to a defined VESSL Dataset.
- Volume:Transfer results or logs to VESSL Storage, which are project-specific storage volumes.
- Object Storage: Save outputs to cloud storage solutions such as AWS S3 or Google Cloud Storage.
Start commands
Specify the start command to initiate the ML task within the container. You can put multiple commands by using the&& command or a new line separation.

Interactive
Enable features like Jupyter Notebook and SSH connections for interactive sessions.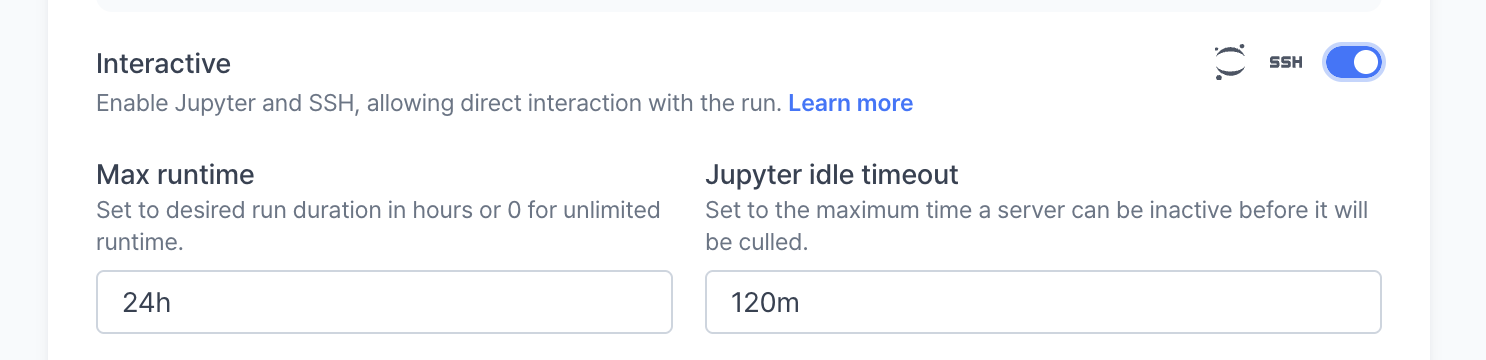
Port
Configure port settings for protocols (HTTP/TCP), specified port numbers, and descriptive names.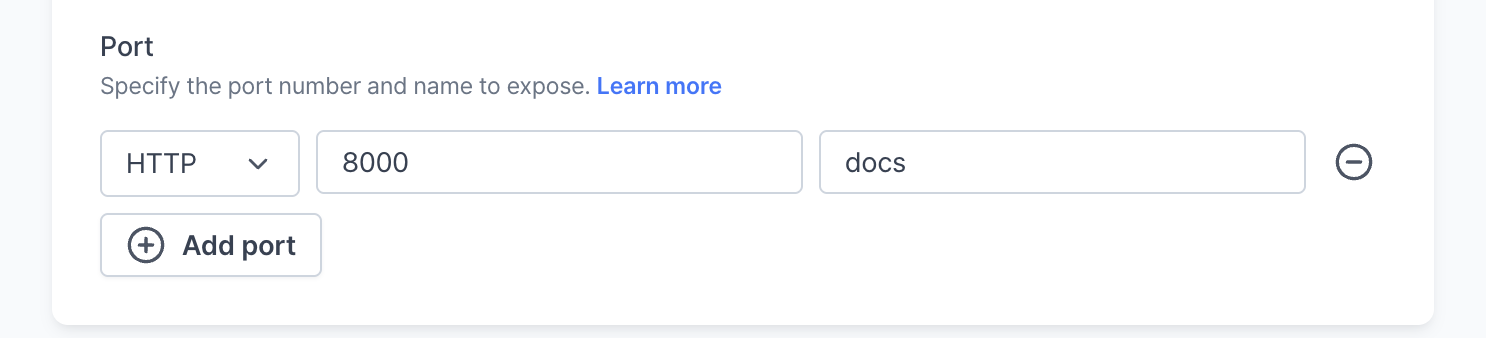
Variables
Variables in the context of machine learning runs are crucial for configuring the runtime environment and securing sensitive information. Here’s how environment variables and secrets can be effectively utilized: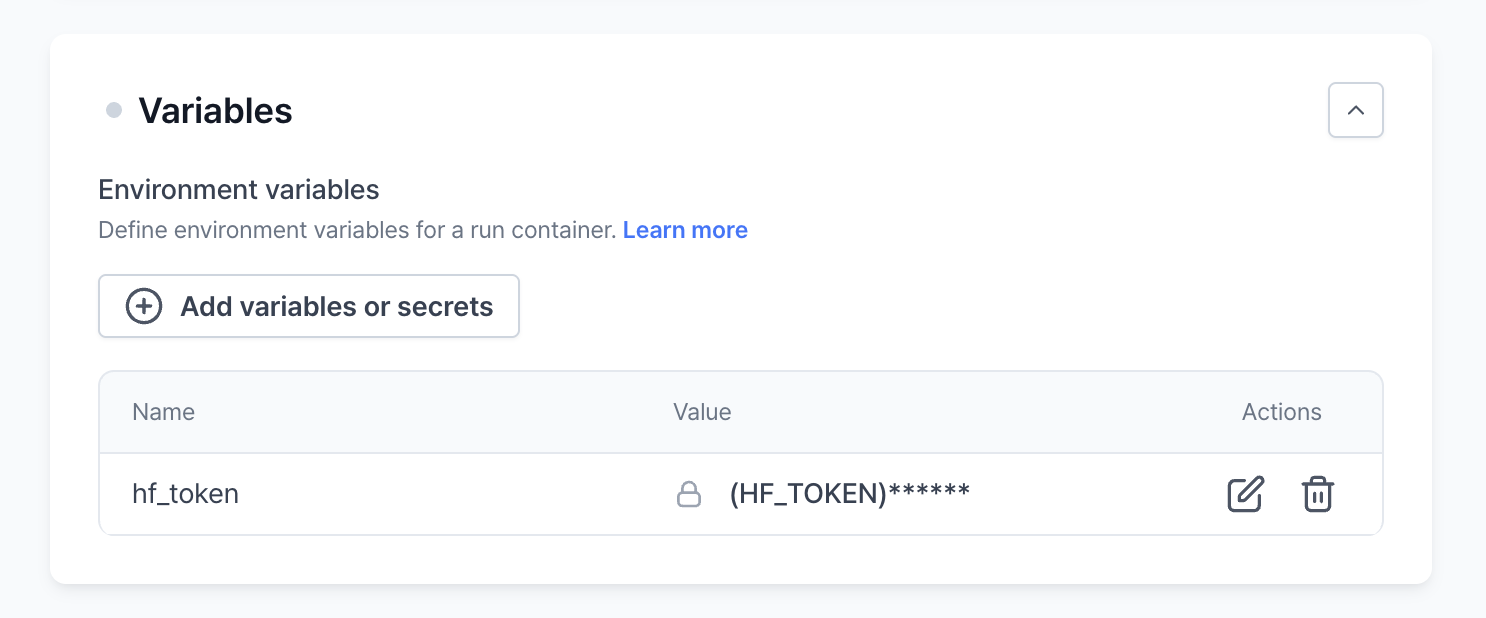
Environment variables
Environment variables allow you to dynamically set configuration parameters that the container can access at runtime. Common use cases include:- Hyperparameters: Set values like
learning_rateorbatch_sizedirectly via environment variables, allowing easy adjustments without modifying the underlying application code. - Configuration Parameters: Adjust runtime settings such as logging levels or feature toggles based on the deployment environment or specific requirements of the run.
Secret
Secrets are used to handle sensitive information that should not be exposed or hardcoded in your application’s code or configuration files. They are securely injected into the run environment and are critical for:- API Keys: Securely manage access to external services, such as Hugging Face models or cloud resources, by using API keys like
HF_TOKENor cloud provider credentials. - Authentication Tokens: Handle user or service authentication seamlessly, ensuring that tokens like the Weights & Biases key
WANDB_API_KEYremain secure and are not logged or exposed.
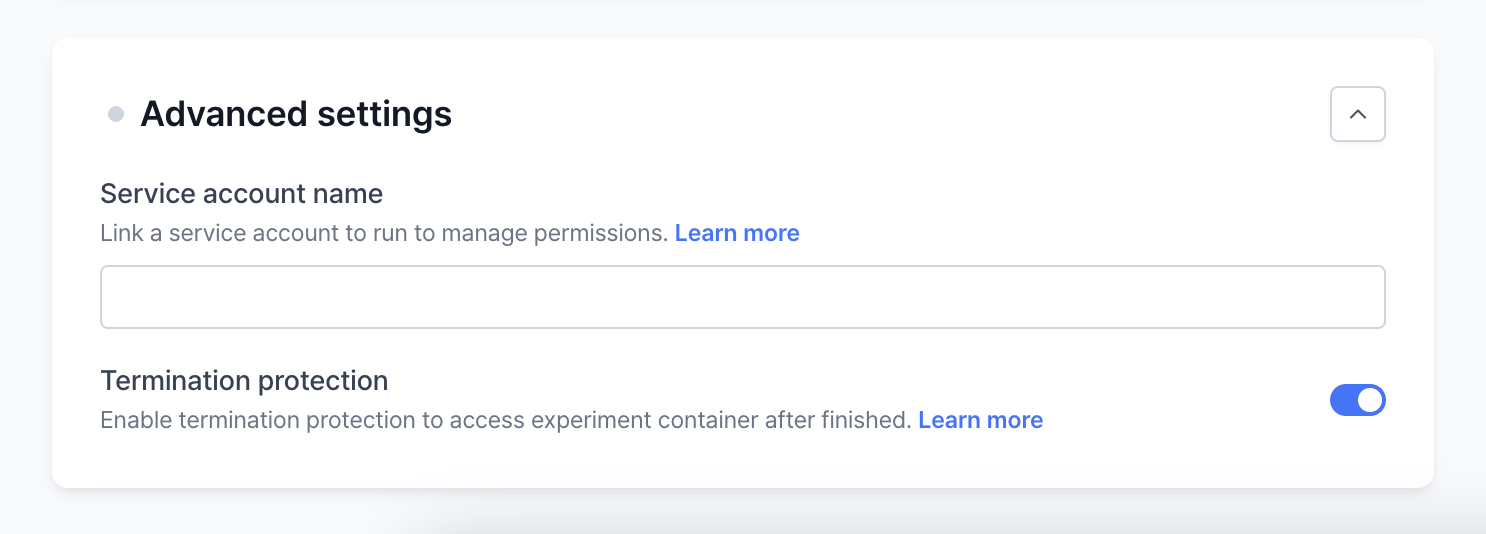
Advanced settings
Advanced settings allow you to customize the run environment further, including: