VESSL — Control plane for machine learning and computing
VESSL provides a unified interface for training and deploying AI models on the cloud. Simply define your GPU resource and pinpoint to your code & dataset. VESSL does the orchestration & heavy lifting for you:- Create a GPU-accelerated container with the right Docker Image.
- Mount your code and dataset from GitHub, Hugging Face, Amazon S3, and more.
- Launches the workload on our fully managed GPU cloud.
One any cloud, at any scale
Instantly scale workloads across multiple clouds.

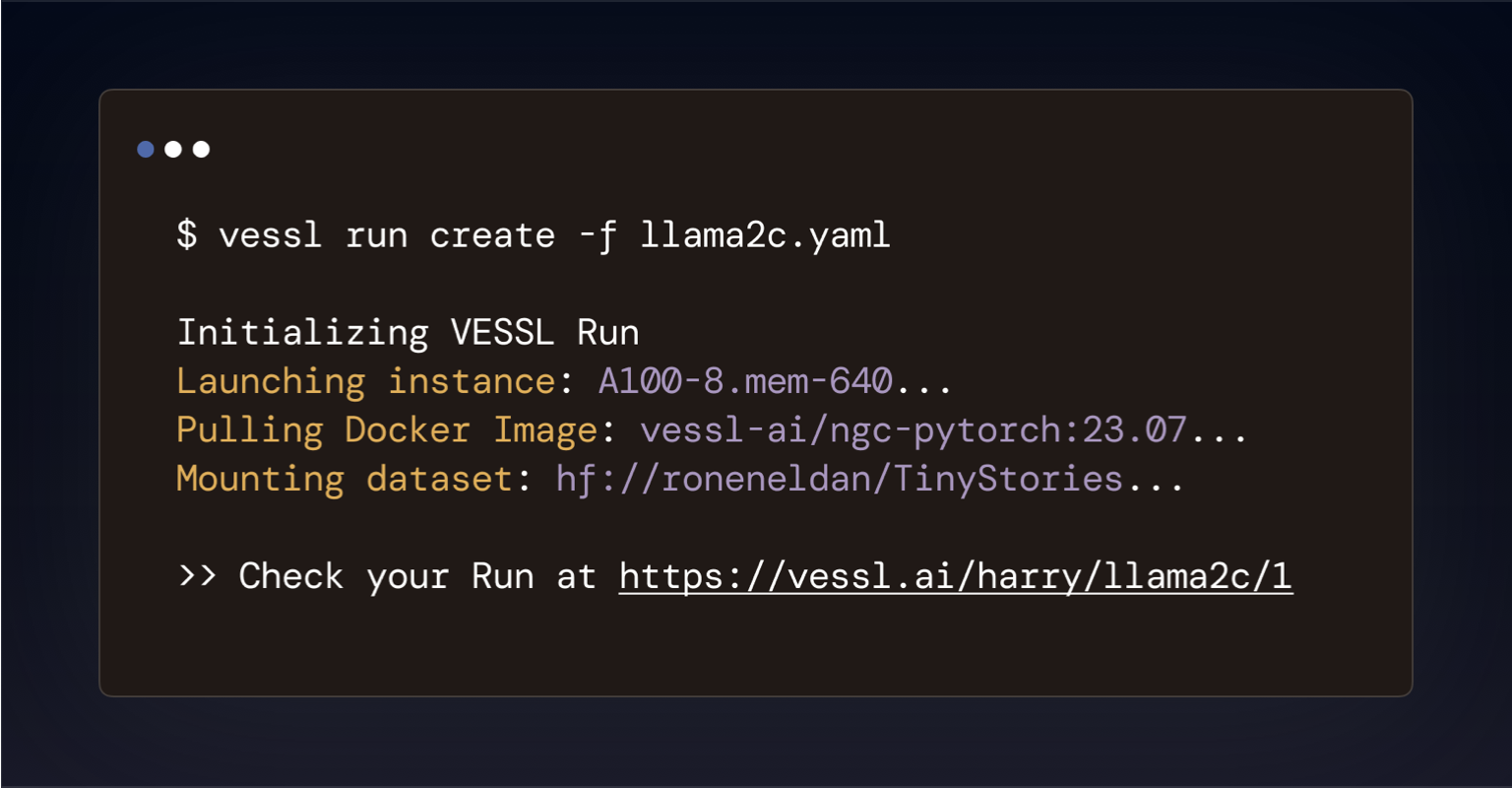
Streamlined interface
Launch any AI workloads with a unified YAML definition.
End-to-end coverage
A single platform for fine-tuning to deployment.
A centralized compute platform
Optimize GPU usage and save up to 80% in cloud.
What can you do?
- Run compute-intensive AI workloads remotely within seconds.
- Fine-tune LLMs with distributed training and auto-failover with zero-to-minimum setup.
- Scale training and inference workloads horizontally.
- Deploy an interactive web applicaiton for your model.
- Serve your AI models as web endpoints.
How to get started
Head over to VESSL and sign up for a free account. Nodocker build or kubectl get.
- Create your account on VESSL.
- Install our Python package —
pip install vessl. - Follow our Quickstart guide or try out our example models at VESSL Hub.
How does it work?
VESSL abstracts the obscure infrastructure and complex backends inherent to launching AI workloads into a simple YAML file, so you don’t have to mess with AWS, Kubernetes, Docker, or more. Here’s an example that launches a chatbot app for Llama 3.2.What’s next?
See VESSL in action with our examples Runs and pre-configured open-source models.Quickstart – Hello, world!
Launch a barebone GPU-accelerated workload on VESSL
GPU-accelerated notebook
Launch a Jupyter Notebook server with an SSH connection
Image Generation Playground
Interactive playground of image generation
Phi-4 fine-tuning
Fine-tune Phi-4 with counselling dataset