Revisions dashboard
The Revisions dashboard offers an overview of the revision statuses. It enables you to modify a specific version of a pipeline that consists of a series of steps.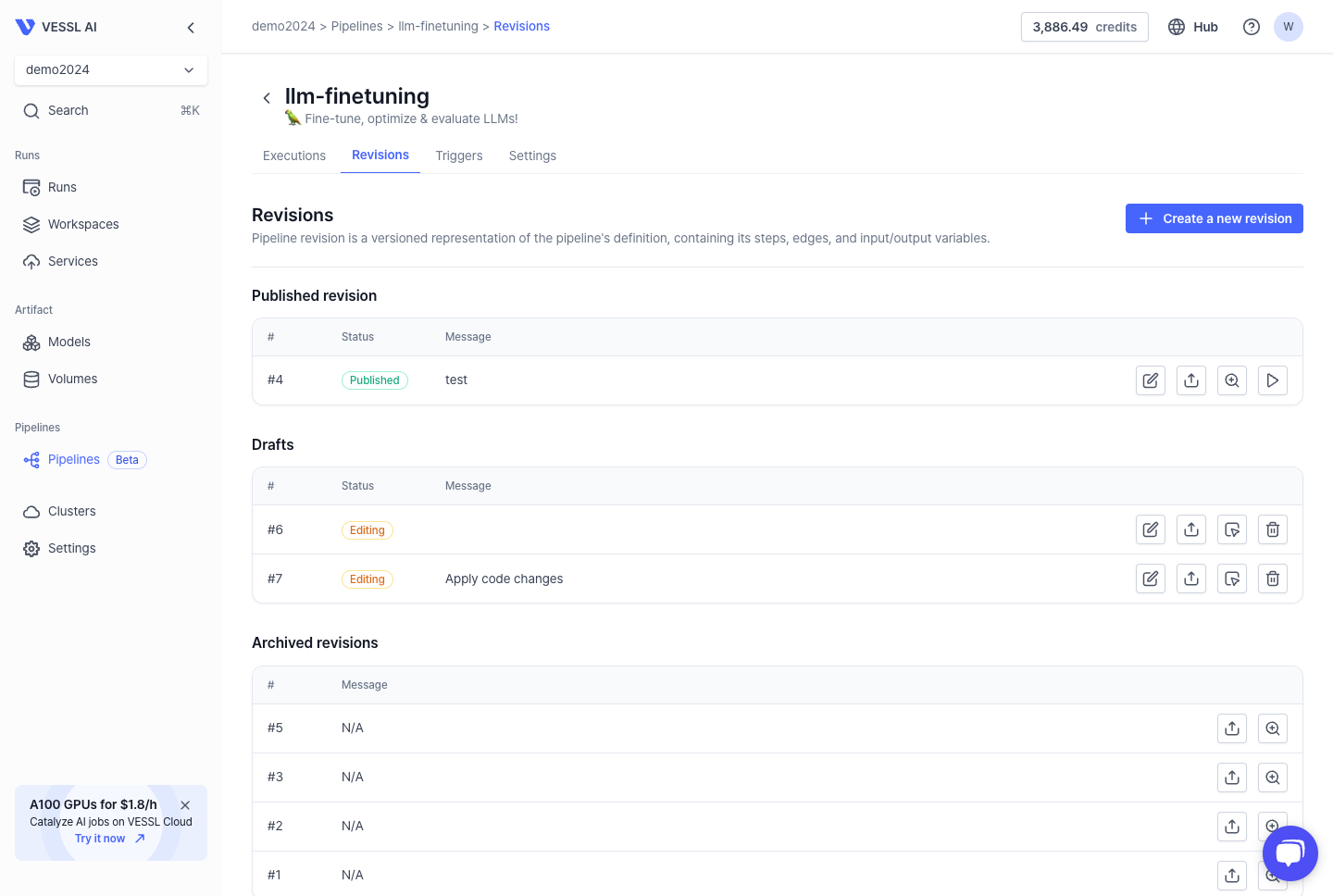
Revision states
There are three states to revise each step:- Published: The pipeline revision is published and available for use in the next execution.
- Drafts (Editable): The pipeline revision is currently in an editable state.
- Archived: The pipeline revision has been archived for future reference.
Revision editor — actions on revisions
You can edit the pipeline revision with two methods:- Web console
- YAML manifest
Edit revision using web console
To edit the pipeline revision using the web console, click edit icon on the editing revision list.- Quick menu: The tool box where you can expand or collapse the tools such as
Step ListandPipeline Variables. - Step list: The list of steps that define each action of the pipeline. You can drag-and-drop the steps to the canvas.
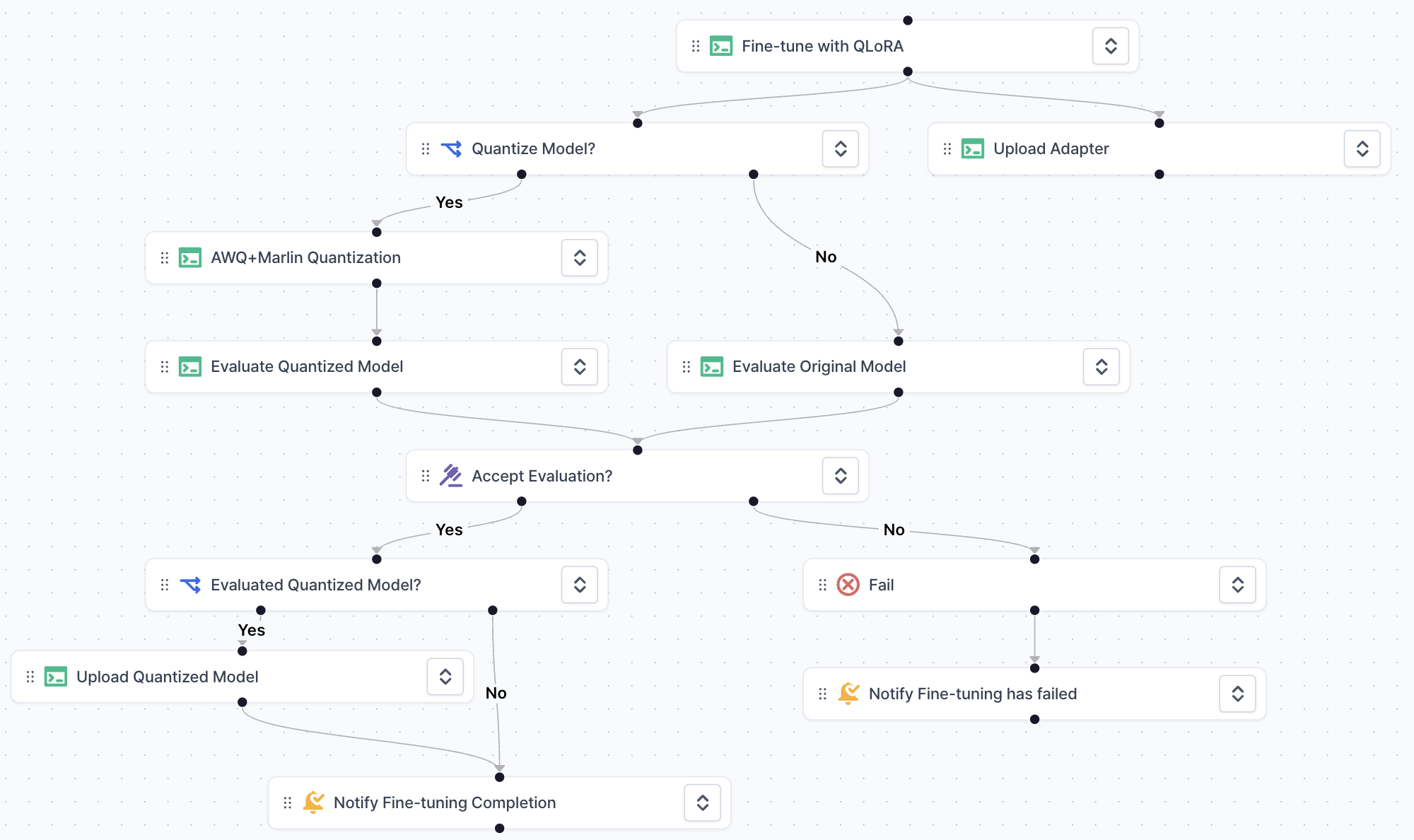
- Dependency graph: The connection of each step and dependency of the editing revision. You can click each step on the graph to edit the details of the step.
- Pipeline variables: The list of pipeline variables that can be injected in the pipeline steps.
Pipeline steps
You can drag and drop the steps from the Step list to the Dependency graph to define the pipeline steps. You can also connect the steps by dragging the arrow from the output of the step to the input of the next step.Learn more about Pipeline steps
Manage your pipeline steps
Pipeline variables
Pipeline variables are working similarly to the environment variables in the pipeline execution. You can define the pipeline variables in the Variables tab and use them in the pipeline steps.Learn more about Pipeline variables
Manage your pipeline environment
Publish button on the top right corner to publish the revision.
Edit revision using YAML manifest
Managing pipeline revisions with a YAML manifest allows for easy tracking, applying updates, and sharing workflow definitions with others. In Pipeline revisions, there are two ways to import a YAML manifest:- Import YAML file
- Paste a YAML configuration
Sample YAML manifest
Here is the sample YAML manifest for fine-tuning an LLM and uploading the quantized model to the Hugging Face model registry:YAML example
YAML example
Replace the following variables on the sample YAML manifest with your values:
{HUGGINGFACE_TOKEN}: Your Huggingface token to access the model registry{LORA_ADAPTER_NAME}: Huggingface Repository name of QLoRA adapter to upload{QUANTIZED_MODEL_NAME}: Huggingface Repository name of quantized model
llm-finetuning.yaml