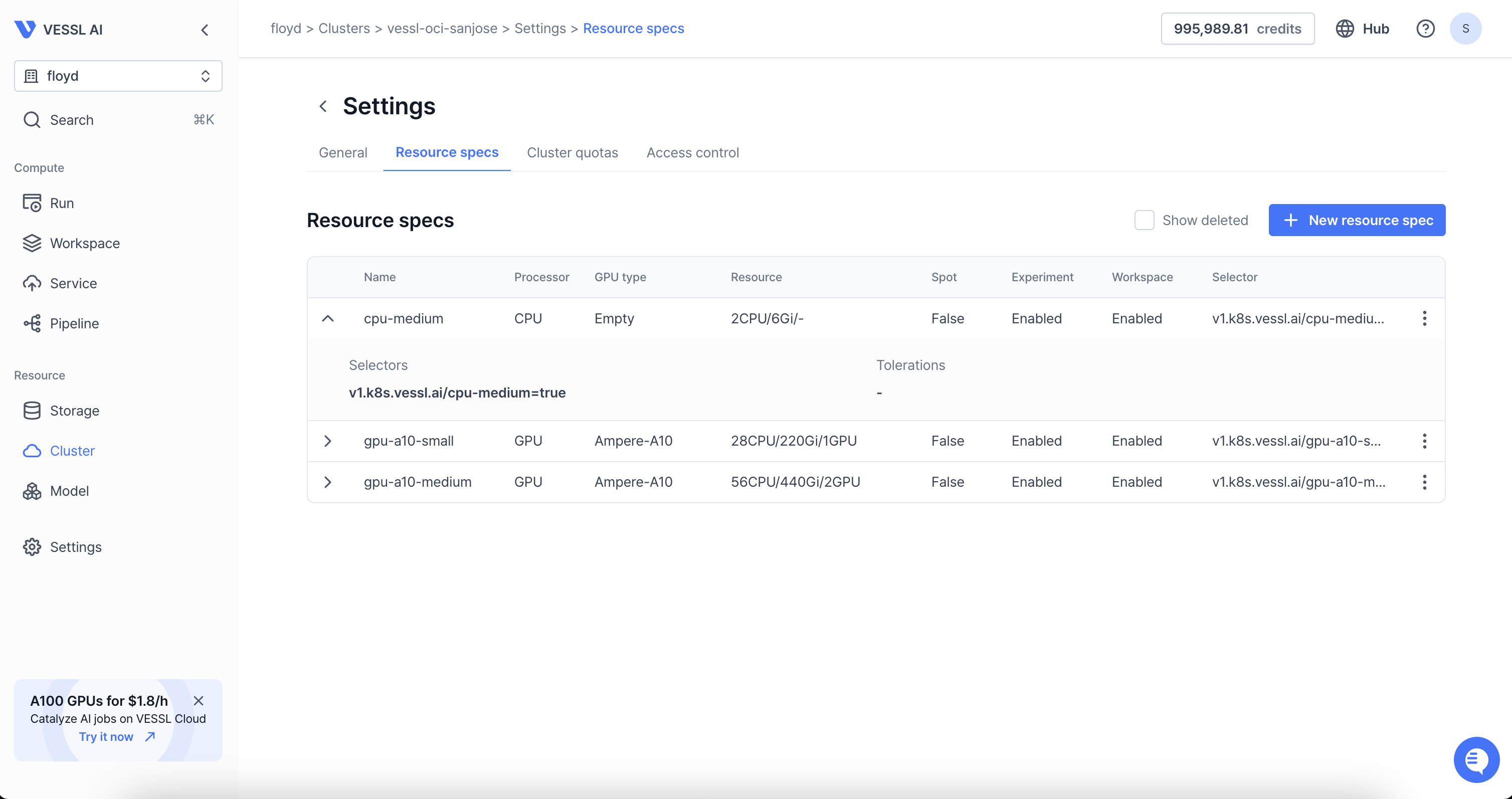
Step-by-step guide
Take a quick 2-minute tour of Resource specs using the demo below.
Name— Set a name for the preset. Use names that well represent the preset likea100-2.mem-16.cpu-6.Processor type— Define the preset by the processor type, either by CPU or GPU.CPU limit— Enter the number of CPUs. Fora100-2.mem-16.cpu-6, enter6.Memory limit— Enter the amount of memory in GB. Fora100-2.mem-16.cpu-6, the number would be 16.
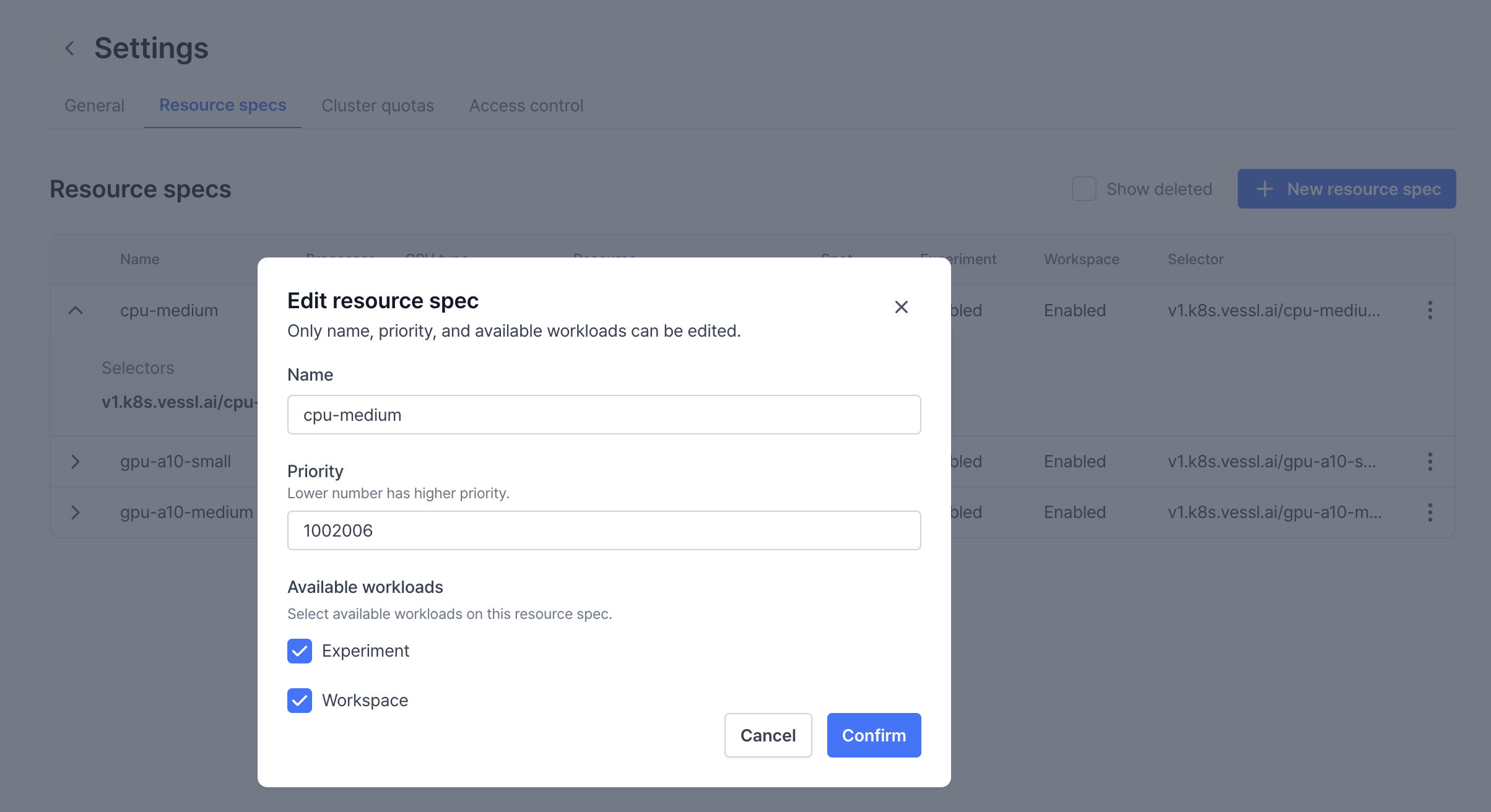
Priority- Assigning different priority values disables the First In, First Out (FIFO) scheduler and executes workloads based on their priority, with lower priority values being processed first. In the example preset above, workloads running oncpu-mediumare always prioritized over workloads on other GPUs. To view the priority assigned to each node, click the Edit button under Resource Specs.GPU type— Specify the GPU model you are using by running thenvidia-smicommand on your server. In the example below, the GPU type isa100-sxm-80gb.
GPU limit— Enter the number of GPUs. Forgpu2.mem16.cpu6, enter2. You can also place decimal values if you are using Multi-Instance GPUs (MIG).Available workloads— Select the type of workloads that can use the preset. With this, you can guide users to use Experiment by preventing them from running Workspace with 4 or 8 GPUs.
Tolerations
Tolerations
Tolerations allow workloads to be scheduled on nodes with specific taints by
matching their conditions. They consist of two key components: Operator and
Effect. Here is an explanation of the available options:
Operator
- Equal
The Toleration is applied only if both the
KeyandValuematch the node’s taint exactly. Example: If a node has a taintkey=value, the Toleration must also specifykey=valueto allow scheduling. - Exists
The Toleration is applied if the
Keyexists, regardless of theValue. Example: If a node has a taint withkey=anything, the Toleration only needs to specifykeyto allow scheduling.
Effect
- NoExecute Workloads that do not tolerate this taint will be evicted immediately from the node. Additionally, they cannot be scheduled onto the node.
- NoSchedule Workloads that do not tolerate this taint will not be scheduled on the node. However, any workloads already running on the node will remain unaffected.
- PreferNoSchedule Kubernetes will attempt to avoid scheduling workloads on nodes with this taint if they do not have a matching Toleration. However, it is not strictly enforced, and workloads may still be scheduled if necessary.
Example use case
If you want to prevent specific workloads from running on nodes reserved for GPU-intensive tasks:- Add a taint to GPU nodes, such as
key=gpu, value=true, effect=NoSchedule. - Configure a Toleration for workloads requiring GPU resources, specifying
key=gpu, value=true, operator=Equal.
Key benefits
Tolerations, in conjunction with taints, offer precise control over workload scheduling, enabling sophisticated policies for workload isolation, enhanced security, and improved cluster stability during node maintenance. They also optimize resource utilization by ensuring workloads run on nodes that meet their operational requirements.Node selectors
Node selectors
Node Selectors allow you to control where workloads are scheduled by
matching specific labels on nodes. They are a simple key-value mechanism used
to constrain workloads to run only on nodes that meet certain criteria.
Key and value
- Key
Specifies the label key on the node that the workload should match. Example:
vessl.ai/role - Value
Specifies the corresponding value of the key. The workload will only be
scheduled on nodes where the label matches this value. Example:
gpu-worker
How node selectors work
When you define a Node selector:- Kubernetes checks for nodes with matching labels (
Key=Value). - Only nodes with labels that match the specified Key-Value pair will be eligible to run the workload.
Example use case
If you want to schedule workloads on nodes reserved for GPU tasks:- Label your GPU nodes with
vessl.ai/role=gpu-worker. - Set a Node Selector in the Resource Spec:
- Key:
vessl.ai/role - Value:
gpu-worker
- Key: