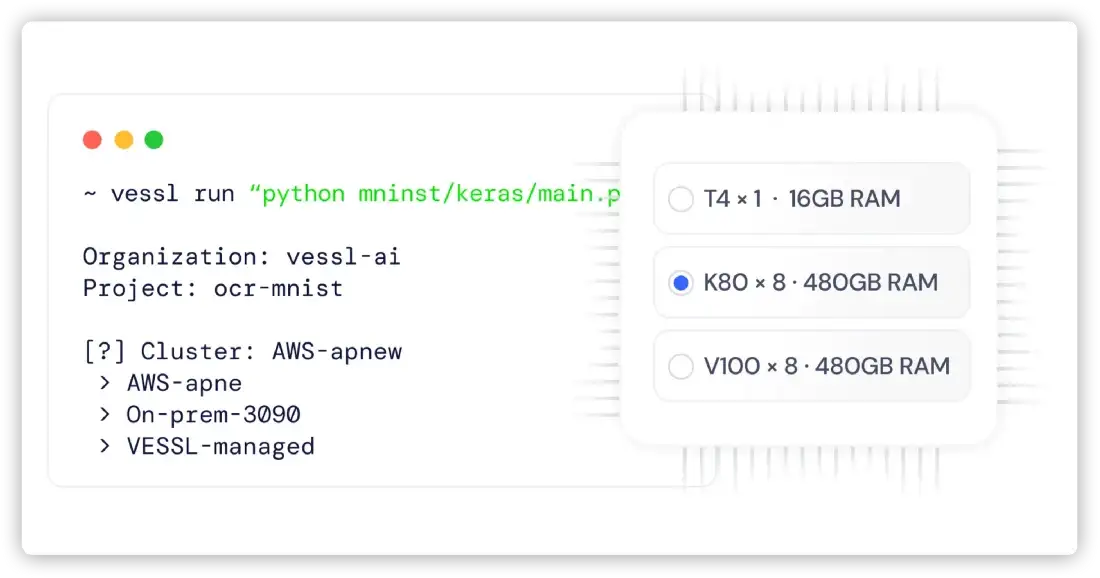
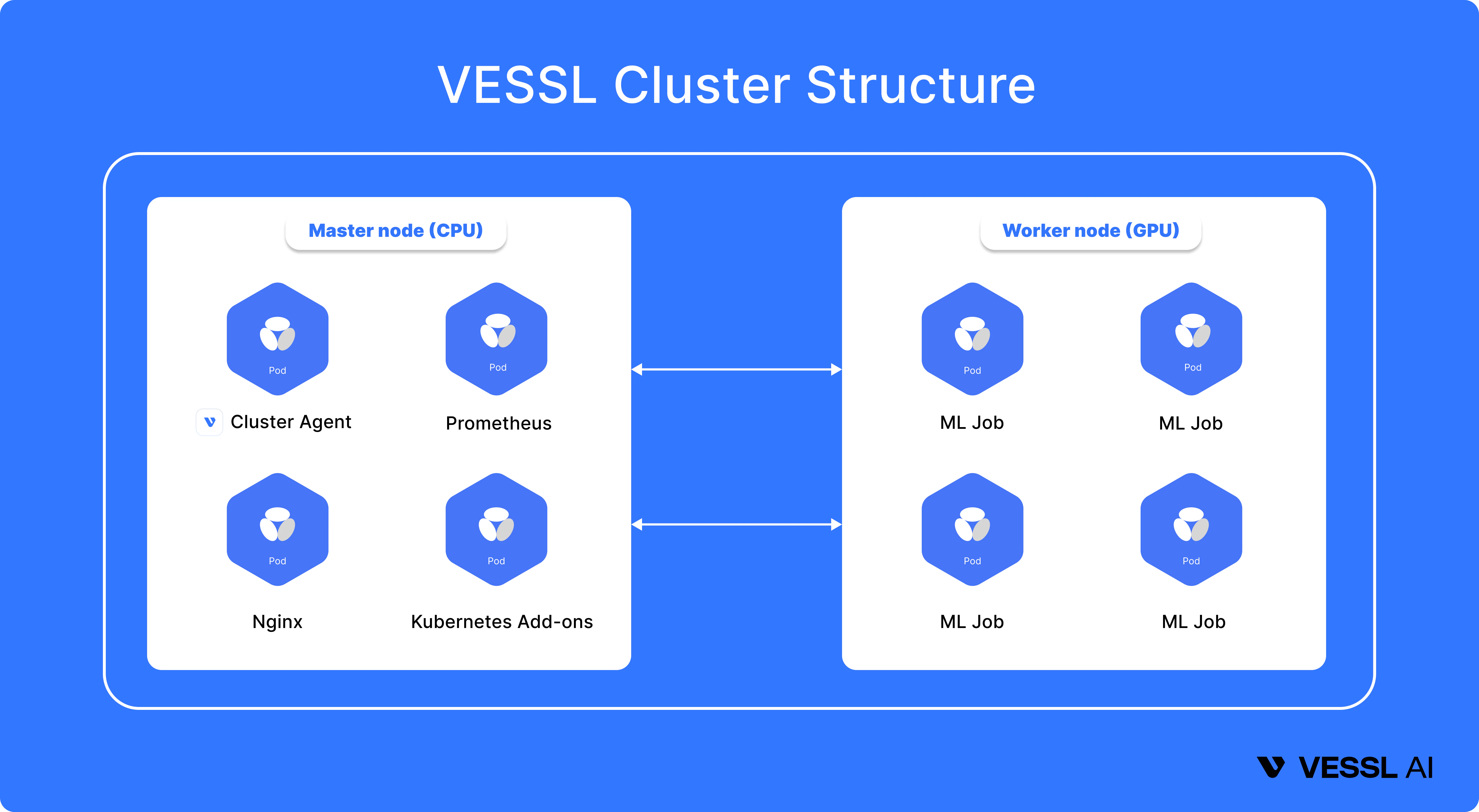
VESSL Cluster enables seamless scaling of containerized ML workloads from a personal laptop to cloud instances or Kubernetes-backed on-premises clusters.
Take a quick tour of VESSL Cluster with the demo below.
- Single-command integration — Set up a hybrid or multi-cloud
infrastructure with a single command.
- GPU-accelerated workloads — Run training, optimization, and inference
tasks on GPUs in seconds
- Resource optimization — Match and scale workloads automatically based on the
required compute resources
- Cluster dashboard — Monitor real-time usage and incident & health status
of clusters down to each node.
- Reproducibility — Record runtime metadata such as hardware and instance
specifications.