 * Host a GPU-accelerated web app built with [Gradio](https://www.gradio.app/)
* Mount model checkpoints from [Hugging Face](https://huggingface.co/)
* Open up a port to an interactive workload for inference
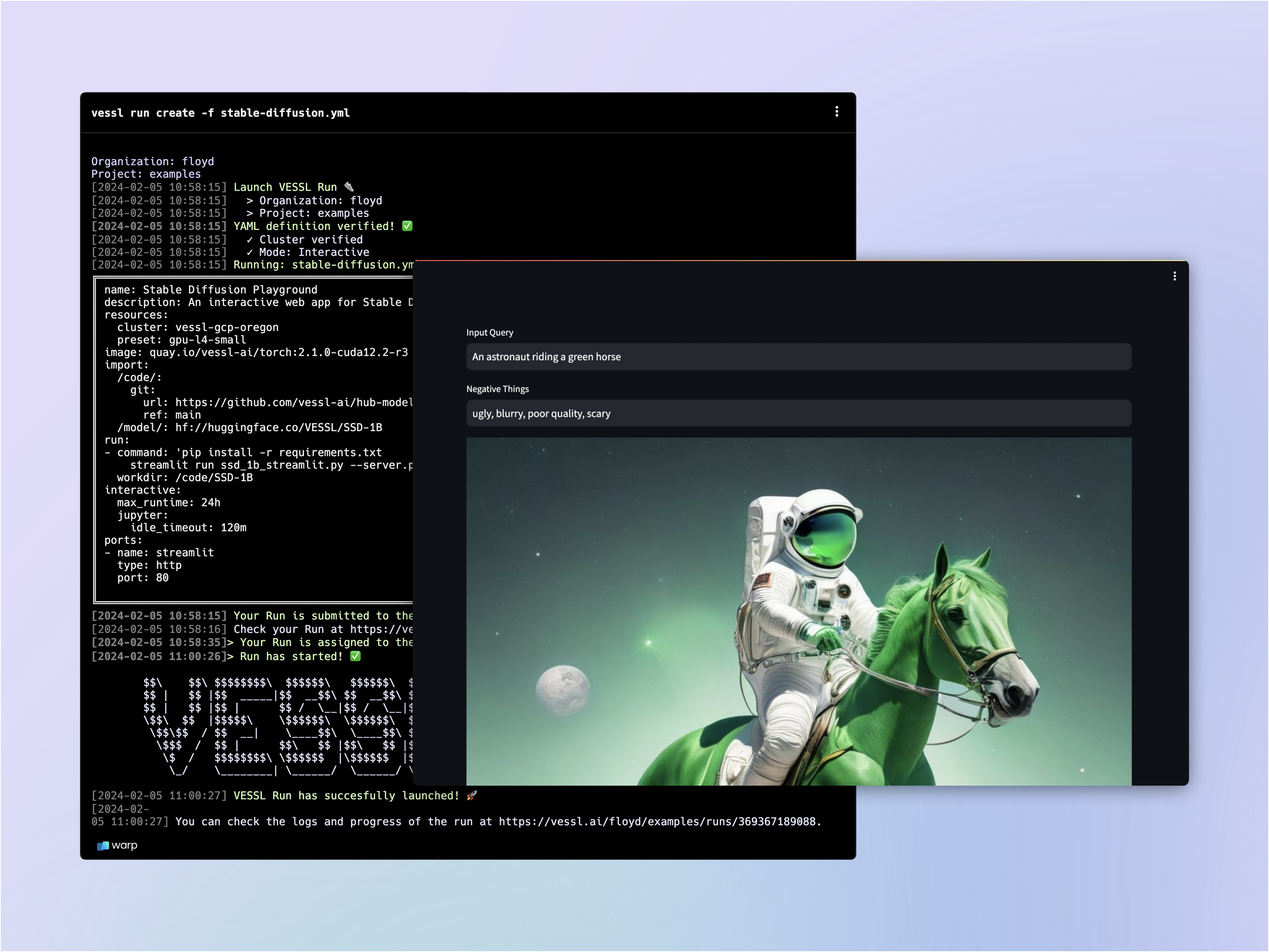
## Writing the YAML file
Let's fill in the `image-generation.yaml` file.
* Host a GPU-accelerated web app built with [Gradio](https://www.gradio.app/)
* Mount model checkpoints from [Hugging Face](https://huggingface.co/)
* Open up a port to an interactive workload for inference
## Writing the YAML file
Let's fill in the `image-generation.yaml` file.
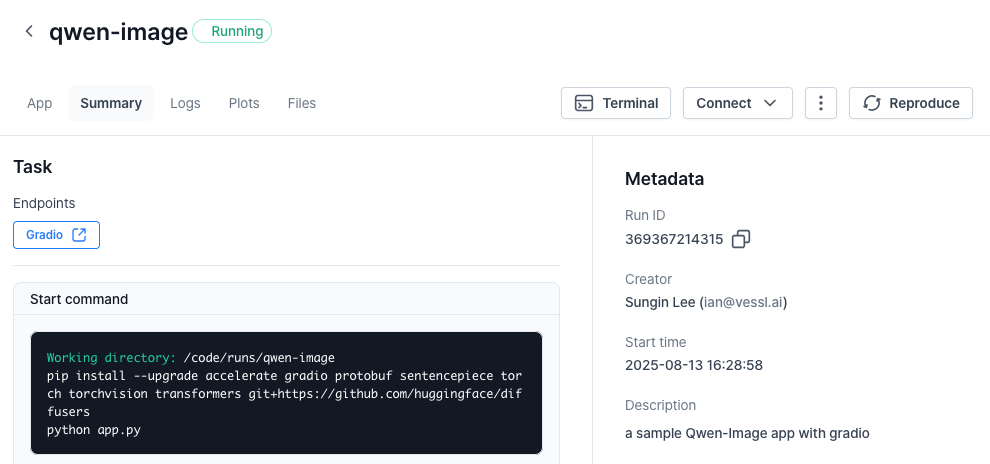
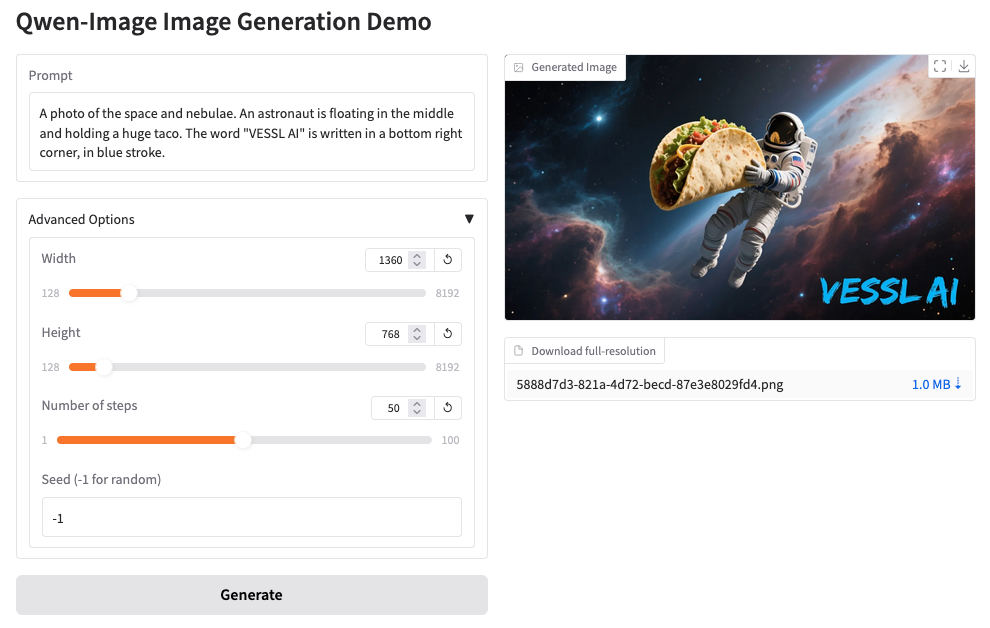 ## Using our web interface
You can repeat the same process on the web. Head over to your **[Organization](https://app.vessl.ai)**, select a project, and create a **New run**.
## Using our web interface
You can repeat the same process on the web. Head over to your **[Organization](https://app.vessl.ai)**, select a project, and create a **New run**.